publications
publications by categories in reversed chronological order.
2025
- NeurIPS25VidEmo: Affective-Tree Reasoning for Emotion-Centric Video Foundation ModelsZhicheng Zhang, Weicheng Wang, Yongjie Zhu, Wenyu Qin, Pengfei Wan, Di Zhang, Jufeng YangIn Advances in Neural Information Processing Systems 2025
Understanding and predicting emotion from videos has gathered significant attention in recent studies, driven by advancements in video large language models (VideoLLMs). While advanced methods have made progress in video emotion analysis, the intrinsic nature of emotions poses significant challenges. Emotions are characterized by dynamic and cues-dependent properties, making it difficult to understand complex and evolving emotional states with reasonable rationale. To tackle these challenges, we propose a novel affective cues-guided reasoning framework that unifies fundamental attribute perception, expression analysis, and high-level emotional understanding in a stage-wise manner. At the core of our approach is a family of video emotion foundation models (VidEmo), specifically designed for emotion reasoning and instruction-following. These models undergo a two-stage tuning process: first, curriculum emotion learning for injecting emotion knowledge, followed by affective-tree reinforcement learning for emotion reasoning. Moreover, we establish a foundational data infrastructure and introduce a emotion-centric fine-grained dataset (Emo-CFG) consisting of 2.1M diverse instruction-based samples. Emo-CFG includes explainable emotional question-answering, fine-grained captions, and associated rationales, providing essential resources for advancing emotion understanding tasks. Experimental results demonstrate that our approach achieves competitive performance, setting a new milestone across 15 face perception tasks.
@inproceedings{zhang2025VidEmo, author = {Zhang, Zhicheng and Wang, Weicheng and Zhu, Yongjie and Qin, Wenyu and Wan, Pengfei and Zhang, Di and Yang, Jufeng}, title = {VidEmo: Affective-Tree Reasoning for Emotion-Centric Video Foundation Models}, booktitle = {Advances in Neural Information Processing Systems}, year = {2025}, } - ICML25 SpotlightMODA: MOdular Duplex Attention for Multimodal Perception, Cognition, and Emotion UnderstandingZhicheng Zhang, Wuyou Xia, Chenxi Zhao, Zhou Yan, Xiaoqiang Liu, Yongjie Zhu, Wenyu Qin, Pengfei Wan, Di Zhang, Jufeng YangIn Proceedings of the 42nd International Conference on Machine Learning (ICML) 2025
Multimodal large language models (MLLMs) recently showed strong capacity in integrating data among multiple modalities, empowered by a generalizable attention architecture. Advanced methods predominantly focus on language-centric tuning while less exploring multimodal tokens mixed through attention, posing challenges in high-level tasks that require fine-grained cognition and emotion understanding. In this work, we identify the attention deficit disorder problem in multimodal learning, caused by inconsistent cross-modal attention and layer-by-layer decayed attention activation. To address this, we propose a novel attention mechanism, termed MOdular Duplex Attention (MODA), simultaneously conducting the inner-modal refinement and inter-modal interaction. MODA employs a correct-after-align strategy to effectively decouple modality alignment from cross-layer token mixing. In the alignment phase, tokens are mapped to duplex modality spaces based on the basis vectors, enabling the interaction between visual and language modality. Further, the correctness of attention scores is ensured through adaptive masked attention, which enhances the model’s flexibility by allowing customizable masking patterns for different modalities. Extensive experiments on 21 benchmark datasets verify the effectiveness of MODA in perception, cognition, and emotion tasks.
@inproceedings{zhang2025moda, author = {Zhang, Zhicheng and Xia, Wuyou and Zhao, Chenxi and Yan, Zhou and Liu, Xiaoqiang and Zhu, Yongjie and Qin, Wenyu and Wan, Pengfei and Zhang, Di and Yang, Jufeng}, title = {MODA: MOdular Duplex Attention for Multimodal Perception, Cognition, and Emotion Understanding}, booktitle = {Proceedings of the 42nd International Conference on Machine Learning (ICML)}, year = {2025}, } - 情智兼备数字人与机器人研究进展赵思成, 丰一帆, 张知诚, 孙斌, 张盛平, 高跃, 杨巨峰, 刘敏, 姚鸿勋, 王耀南中国图像图形学报 2025
情智兼备数字人与机器人技术旨在开发具备情感理解和个性化响应能力的智能系统,这一方向逐渐成为学术界和社会各界的研究焦点.本文围绕脑认知驱动的情感机理、多模态情智大模型的融合与解译、个性化情感表征与动态计算以及可交互情绪化内容生成调控等4个方面,系统性地分析情智兼备数字人与机器人技术的研究现状与进展.展望未来,情智兼备数字人与机器人将在医疗陪护、智能教育和心理健康等领域展现出广阔的应用前景,并将在提升人机交互的自然性、个性化服务以及用户体验方面发挥重要作用.
@article{赵思成2025情智兼备, author = {赵思成 and 丰一帆 and 张知诚 and 孙斌 and 张盛平 and 高跃 and 杨巨峰 and 刘敏 and 姚鸿勋 and 王耀南}, title = {情智兼备数字人与机器人研究进展}, journal = {中国图像图形学报}, year = {2025}, }
2024
- ExtDM: Distribution Extrapolation Diffusion Model for Video PredictionZhicheng Zhang, Junyao Hu, Wentao Cheng, Danda Paudel, Jufeng YangIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Video prediction is a challenging task due to its nature of uncertainty, especially for forecasting a long period. To model the temporal dynamics, advanced methods benefit from the recent success of diffusion models, and repeatedly refine the predicted future frames with 3D spatiotemporal U-Net. However, there exists a gap between the present and future and the repeated usage of U-Net brings a heavy computation burden. To address this, we propose a diffusion-based video prediction method that predicts future frames by extrapolating the present distribution of features, namely ExtDM. Specifically, our method consists of three components: (i) a motion autoencoder conducts a bijection transformation between video frames and motion cues; (ii) a layered distribution adaptor module extrapolates the present features in the guidance of Gaussian distribution; (iii) a 3D U-Net architecture specialized for jointly fusing guidance and features among the temporal dimension by spatiotemporal-window attention. Extensive experiments on four popular benchmarks covering short- and long-term video prediction verify the effectiveness of ExtDM.
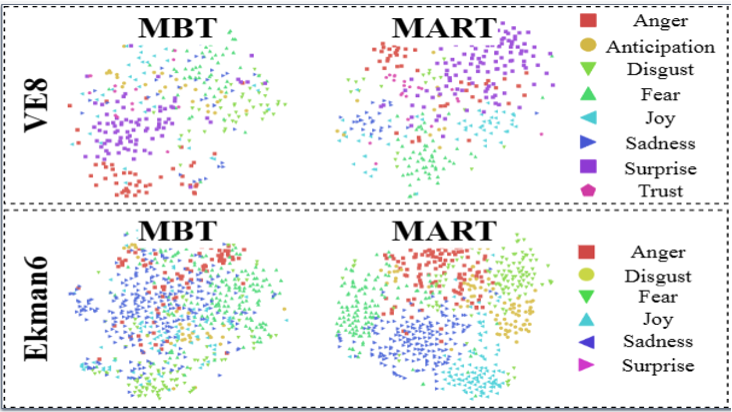
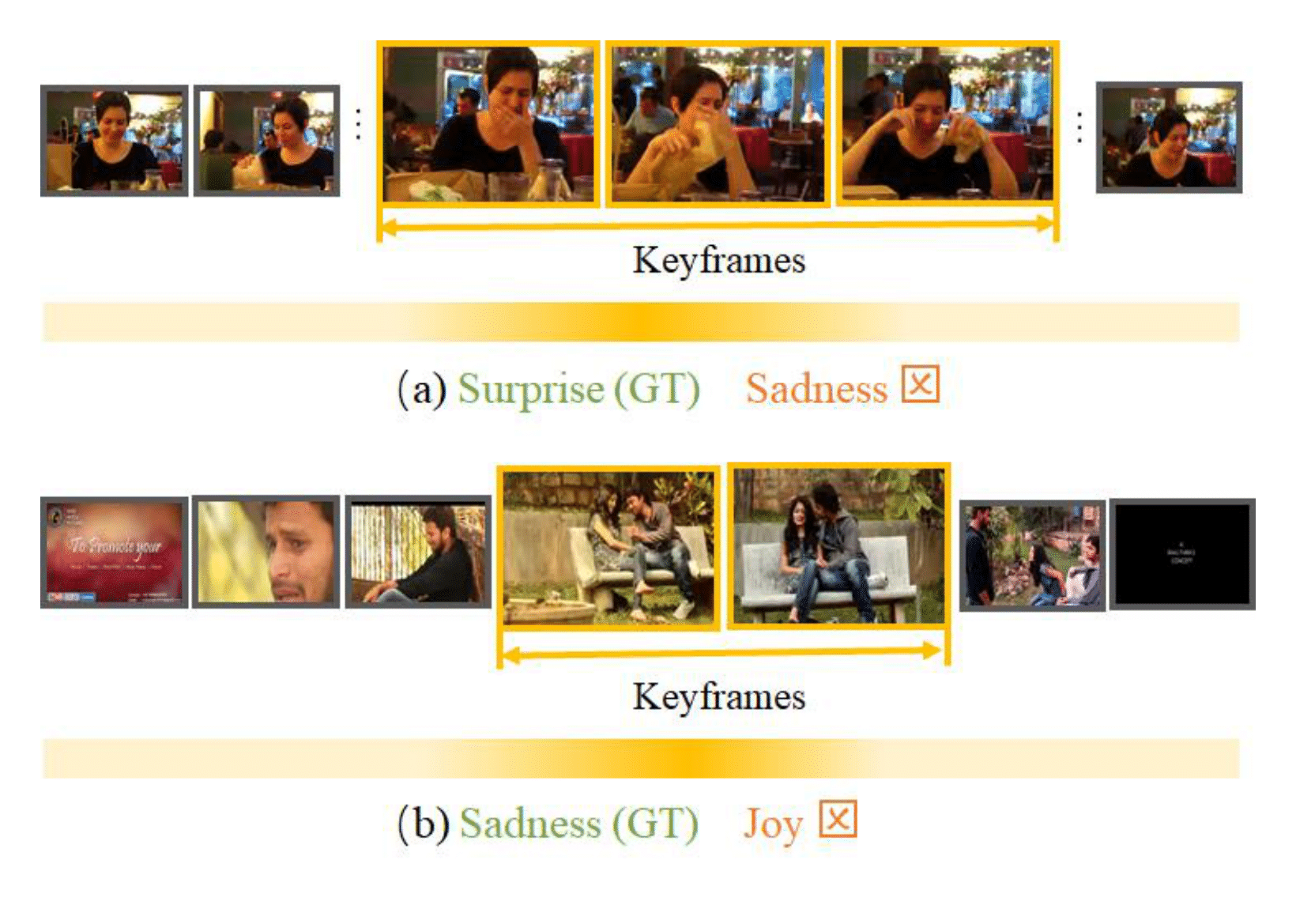
@inproceedings{zhang2024distribution, author = {Zhang, Zhicheng and Hu, Junyao and Cheng, Wentao and Paudel, Danda and Yang, Jufeng}, title = {ExtDM: Distribution Extrapolation Diffusion Model for Video Prediction}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024}, } - MART: Masked Affective RepresenTation Learning via Masked Temporal Distribution DistillationZhicheng Zhang, Pancheng Zhao, Eunil Park, Jufeng YangIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Limited training data is a long-standing problem for video emotion analysis (VEA). Existing works leverage the power of large-scale image datasets for transferring while failing to extract the temporal correlation of affective cues in the video. Inspired by psychology research and empirical theory, we verify that the degree of emotion may vary in different segments of the video, thus introducing the sentiment complementary and emotion intrinsic among temporal segments. Motivated by this, we propose an MAE-style method for learning robust affective representation of videos via masking, termed MART. The method is comprised of emotional lexicon extraction and masked emotion recovery. First, we extract the affective cues of the lexicon and verify the extracted one by computing its matching score with video content. The hierarchical verification strategy is proposed, in terms of sentiment and emotion, to identify the matched cues alongside the temporal dimension. Then, with the verified cues, we propose masked affective modeling to recover temporal emotion distribution. We present temporal affective complementary learning that pulls the complementary part and pushes the intrinsic part of masked multimodal features, for learning robust affective representation. Under the constraint of affective complementary, we leverage cross-modal attention among features to mask the video and recover the degree of emotion among segments. Extensive experiments on three benchmark datasets demonstrate the superiority of our method in video sentiment analysis, video emotion recognition, multimodal sentiment analysis, and multimodal emotion recognition.
@inproceedings{zhang2024masked, author = {Zhang, Zhicheng and Zhao, Pancheng and Park, Eunil and Yang, Jufeng}, title = {MART: Masked Affective RepresenTation Learning via Masked Temporal Distribution Distillation}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024}, } - LAKE-RED: Camouflaged Images Generation by Latent Background Knowledge Retrieval-Augmented DiffusionPancheng Zhao, Peng Xu, Pengda Qin, Deng-Ping Fan, Zhicheng Zhang, Guoli Jia, Bowen Zhou, Jufeng YangIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Camouflaged vision perception is an important vision task with numerous practical applications. Due to the expensive collection and labeling costs, this community struggles with a major bottleneck that the species category of its datasets is limited to a small number of object species. However, the existing camouflaged generation methods require specifying the background manually, thus failing to extend the camouflaged sample diversity in a low-cost manner. In this paper, we propose a Latent Background Knowledge Retrieval-Augmented Diffusion (LAKE-RED) for camouflaged image generation. To our knowledge, our contributions mainly include: (1) For the first time, we propose a camouflaged generation paradigm that does not need to receive any background inputs. (2) Our LAKE-RED is the first knowledge retrieval-augmented method with interpretability for camouflaged generation, in which we propose an idea that knowledge retrieval and reasoning enhancement are separated explicitly, to alleviate the task-specific challenges. Moreover, our method is not restricted to specific foreground targets or backgrounds, offering a potential for extending camouflaged vision perception to more diverse domains. (3) Experimental results demonstrate that our method outperforms the existing approaches, generating more realistic camouflage images.
@inproceedings{zhao2024camouflaged, author = {Zhao, Pancheng and Xu, Peng and Qin, Pengda and Fan, Deng-Ping and Zhang, Zhicheng and Jia, Guoli and Zhou, Bowen and Yang, Jufeng}, title = {LAKE-RED: Camouflaged Images Generation by Latent Background Knowledge Retrieval-Augmented Diffusion}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024}, }

2023
- 属性知识引导的自适应视觉感知与结构理解研究进展张知诚, 杨巨峰, 程明明, 林巍峣, 汤进, 李成龙, 刘成林模式识别与人工智能 2023
机器通过自适应感知从环境中提取人类可理解的信息,从而在开放场景中构建类人智能.因属性知识具有类别无关的特性,以其为基础构建的感知模型与算法引起广泛关注.文中首先介绍属性知识引导的自适应视觉感知与结构理解的相关任务,分析其适用场景.然后,总结四个关键方面的代表性工作.1)视觉基元属性知识提取方法,涵盖底层几何属性和高层认知属性;2)属性知识引导的弱监督视觉感知,包括数据标签受限情况下的弱监督学习与无监督学习;3)图像无监督自主学习,包括自监督对比学习和无监督共性学习;4)场景图像结构化表示和理解及其应用.最后,讨论目前研究存在的不足,分析有价值的潜在研究方向,如大规模多属性基准数据集构建、多模态属性知识提取、属性知识感知模型场景泛化、轻量级属性知识引导的模型开发、场景图像表示的实际应用等.
@article{张知诚2023属性知识引导的自适应视觉感知与结构理解研究进展, title = {属性知识引导的自适应视觉感知与结构理解研究进展}, author = {张知诚 and 杨巨峰 and 程明明 and 林巍峣 and 汤进 and 李成龙 and 刘成林}, journal = {模式识别与人工智能}, volume = {36}, number = {12}, pages = {1104--1126}, year = {2023}, } - Multiple Planar Object TrackingZhicheng Zhang, Shengzhe Liu, Jufeng YangIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2023
Tracking both location and pose of multiple planar objects (MPOT) is of great significance to numerous real-world applications. The greater degree-of-freedom of planar objects compared with common objects makes MPOT far more challenging than well-studied object tracking, especially when occlusion occurs. To address this challenging task, we are inspired by amodal perception that humans jointly track visible and invisible parts of the target, and propose a tracking framework that unifies appearance perception and occlusion reasoning. Specifically, we present a dual branch network to track the visible part of planar objects, including vertexes and mask. Then, we develop an occlusion area localization strategy to infer the invisible part, i.e., the occluded region, followed by a two-stream attention network finally refining the prediction. To alleviate the lack of data in this field, we build the first large-scale benchmark dataset, namely MPOT-3K. It consists of 3,717 planar objects from 356 videos, and contains 148,896 frames together with 687,417 annotations. The collected planar objects have 9 motion patterns and the videos are shot in 6 types of indoor and outdoor scenes. Extensive experiments demonstrate the superiority of our proposed method on the newly developed MPOT-3K as well as other two popular single planar object tracking datasets.
@inproceedings{Zhang_2023_ICCV, author = {Zhang, Zhicheng and Liu, Shengzhe and Yang, Jufeng}, title = {Multiple Planar Object Tracking}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, year = {2023}, } - Weakly Supervised Video Emotion Detection and Prediction via Cross-Modal Temporal Erasing NetworkZhicheng Zhang, Lijuan Wang, Jufeng YangIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2023
Automatically predicting the emotions of user-generated videos (UGVs) receives increasing interest recently. However, existing methods mainly focus on a few key visual frames, which may limit their capacity to encode the context that depicts the intended emotions. To tackle that, in this paper, we propose a cross-modal temporal erasing network that locates not only keyframes but also context and audio-related information in a weakly-supervised manner. In specific, we first leverage the intra- and inter-modal relationship among different segments to accurately select keyframes. Then, we iteratively erase keyframes to encourage the model to concentrate on the contexts that include complementary information. Extensive experiments on three challenging benchmark datasets demonstrate that the proposed method performs favorably against the state-of-the-art approaches.
@inproceedings{Zhang_2023_CVPR, author = {Zhang, Zhicheng and Wang, Lijuan and Yang, Jufeng}, title = {Weakly Supervised Video Emotion Detection and Prediction via Cross-Modal Temporal Erasing Network}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2023}, } - PlaneSeg: Building a Plug-In for Boosting Planar Region SegmentationZhicheng Zhang, Song Chen, Zichuan Wang, Jufeng YangIEEE Transactions on Neural Networks and Learning Systems 2023
Existing methods in planar region segmentation suffer the problems of vague boundaries and failure to detect small-sized regions. To address these, this study presents an end-to-end framework, named PlaneSeg, which can be easily integrated into various plane segmentation models. Specifically, PlaneSeg contains three modules, namely the edge feature extraction module, the multi-scale module, and the resolution-adaptation module. First, the edge feature extraction module produces edge-aware feature maps for finer segmentation boundaries. The learned edge information acts as a constraint to mitigate inaccurate boundaries. Second, the multi-scale module combines feature maps of different layers to harvest spatial and semantic information from planar objects. The multiformity of object information can help recognize small-sized objects to produce more accurate segmentation results. Third, the resolution-adaptation module fuses the feature maps produced by the two aforementioned modules. For this module, a pair-wise feature fusion is adopted to resample the dropped pixels and extract more detailed features. Extensive experiments demonstrate that PlaneSeg outperforms other state-of-the-art approaches on three downstream tasks, including plane segmentation, 3D plane reconstruction, and depth prediction.
@article{10097456, author = {Zhang, Zhicheng and Chen, Song and Wang, Zichuan and Yang, Jufeng}, journal = {IEEE Transactions on Neural Networks and Learning Systems}, title = {PlaneSeg: Building a Plug-In for Boosting Planar Region Segmentation}, year = {2023}, volume = {1}, number = {1}, pages = {1-15}, doi = {10.1109/TNNLS.2023.3262544}, }

2022
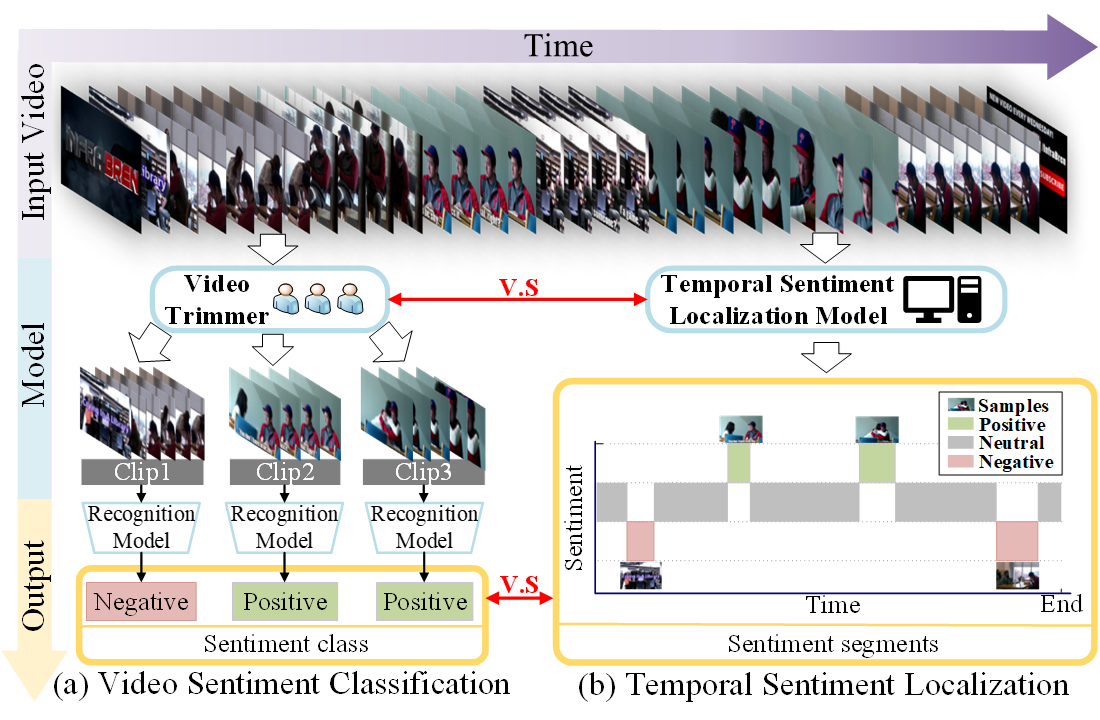
- Temporal Sentiment Localization: Listen and Look in Untrimmed VideosZhicheng Zhang, Jufeng YangIn Proceedings of the 30th ACM International Conference on Multimedia 2022
Video sentiment analysis aims to uncover the underlying attitudes of viewers, which has a wide range of applications in real world. Existing works simply classify a video into a single sentimental category, ignoring the fact that sentiment in untrimmed videos may appear in multiple segments with varying lengths and unknown locations. To address this, we propose a challenging task, i.e., Temporal Sentiment Localization (TSL), to find which parts of the video convey sentiment. To systematically investigate fully- and weakly-supervised settings for TSL, we first build a benchmark dataset named TSL-300, which is consisting of 300 videos with a total length of 1,291 minutes. Each video is labeled in two ways, one of which is frame-by-frame annotation for the fully-supervised setting, and the other is single-frame annotation, i.e., only a single frame with strong sentiment is labeled per segment for the weakly-supervised setting. Due to the high cost of labeling a densely annotated dataset, we propose TSL-Net in this work, employing single-frame supervision to localize sentiment in videos. In detail, we generate the pseudo labels for unlabeled frames using a greedy search strategy, and fuse the affective features of both visual and audio modalities to predict the temporal sentiment distribution. Here, a reverse mapping strategy is designed for feature fusion, and a contrastive loss is utilized to maintain the consistency between the original feature and the reverse prediction. Extensive experiments show the superiority of our method against the state-of-the-art approaches.
@inproceedings{10.1145/3503161.3548007, author = {Zhang, Zhicheng and Yang, Jufeng}, title = {Temporal Sentiment Localization: Listen and Look in Untrimmed Videos}, year = {2022}, url = {https://doi.org/10.1145/3503161.3548007}, doi = {10.1145/3503161.3548007}, booktitle = {Proceedings of the 30th ACM International Conference on Multimedia}, }