TL;DR: We present MPOT, a new task to track both location and pose of multiple planar objects simultaneously. The first large-scale dataset MPOT-3K is released on here.
Tracking both location and pose of multiple planar objects (MPOT) is of great significance to numerous real-world applications. The greater degree-of-freedom of planar objects compared with common objects makes MPOT far more challenging than well-studied object tracking, especially when occlusion occurs. To address this challenging task, we are inspired by amodal perception that humans jointly track visible and invisible parts of the target, and propose a tracking framework that unifies appearance perception and occlusion reasoning. Specifically, we present a dual branch network to track the visible part of planar objects, including vertexes and mask. Then, we develop an occlusion area localization strategy to infer the invisible part, i.e., the occluded region, followed by a two-stream attention network finally refining the prediction. To alleviate the lack of data in this field, we build the first large-scale benchmark dataset, namely MPOT-3K. It consists of 3,717 planar objects from 356 videos, and contains 148,896 frames together with 687,417 annotations. The collected planar objects have 9 motion patterns and the videos are shot in 6 types of indoor and outdoor scenes.
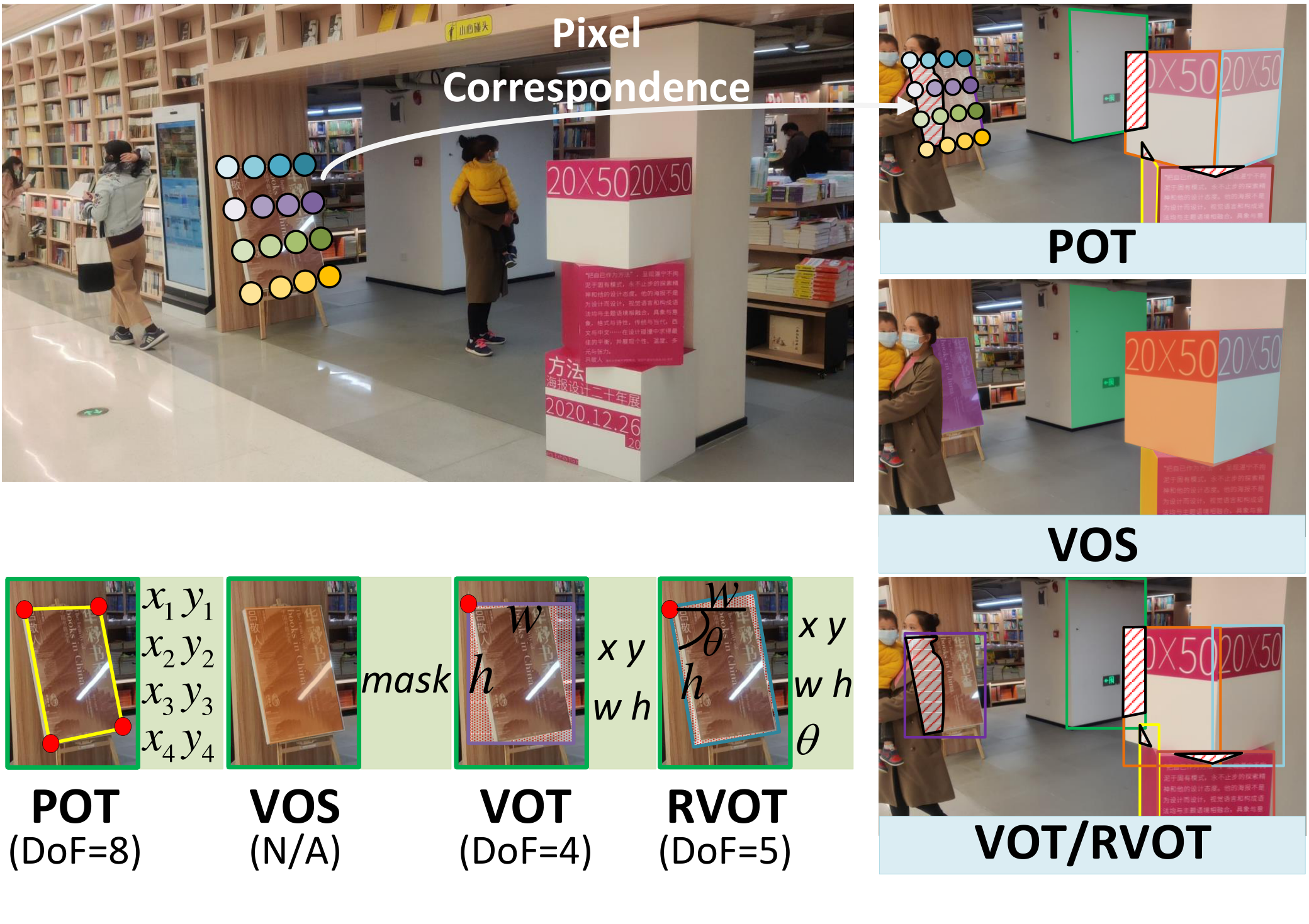
Given an image (a), we present the ground truth for different tasks in (b). The corresponding Degree-of-Freedom (DoF) is reported at the bottom and the details are listed on the right side of each task. In (c), we show the tracking results for box-based tasks (e.g., VOT, RVOT), mask-based tasks (e.g., VOS), and POT, which can find the occluded regions (marked by the red line area) and provide pixel-to-pixel matching correspondence (colored points across frames).
Tracking planar objects is of greater Degree-of-Freedom (DoF). As shown in Fig.1 (b) MPOT tracks both the pose and location of the target, which is described by an arbitrary quadrangle (i.e., four independent vertexes (x1,y1,x2,y2,x3,y3,x4,y4)), whose DoF is 8. In contrast, it only needs to predict the position and size of an object (x,y,w,h) in video object tracking (VOT), and rotated VOT (RVOT) additionally requires the rotation angle. Even compared with video object segmentation (VOS), an alternative that introduces mask at the pixel level, MPOT is a more challenging task. Because MPOT provides the matched correspondence for each pixel within the object region across frames (e.g., colored points in Fig.1 (a)\&(c)), which makes it possible for applications that require positional information like texture mapping. And VOS that tracks the target area instead of per-pixel location can hardly achieve it.
Except for the one in POT that manually occludes the camera, MPOT introduces the occlusion raised by the layered position of multiple targets relative to the camera (see Fig.1 (c)). Besides, the occlusion is more complex than the ones in multiple object tracking (MOT). When occlusion occurs, MPOT estimates the pixel correspondence controlled by homography matrix, which tends to be sensitive and have a high condition number that can reach up to 5e7. That means, even with the tiny movement of the invisible part, it is of huge difficulty for tracking.
We propose the FIRST LARGE-SCALE dataset MPOT-3K, which obtain 356 videos with 3,717 planar objects from 42 scenes. The number of planar objects per video averages 10.44 and can reach 74 at most.




MPOT-3K contains over 9.8 times more annotations and 13.2 times more targets in all video frames than the largest POT dataset POT280. The number of targets is almost 3 times of the popular MOT16 dataset. To the best of our knowledge, MPOT-3K is the first large-scale dataset for the challenging task of MPOT. Another strength of MPOT-3K lies in its diversity, which covers 9 motion patterns and 6 types of scenes. Besides, MPOT-3K introduces more complex occlusions. It occurs in all the scenes, where 39.9% of planar objects are occluded on average. In MPOT-3K, there are 3.6 occlusions happening in a video on average and each occlusion lasts 9.56 seconds.
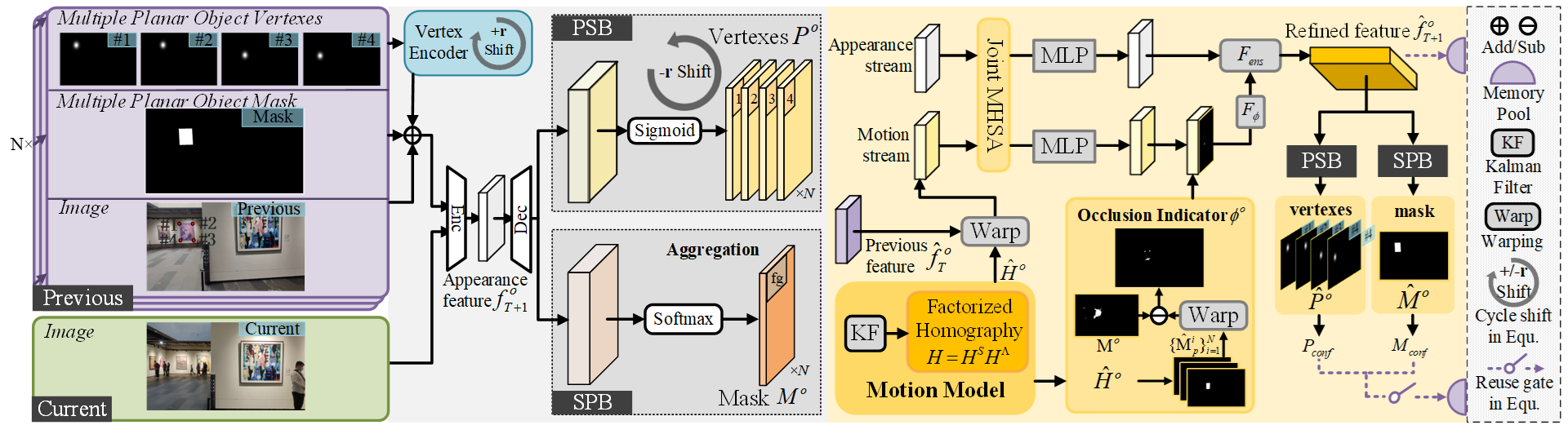
How to track multiple planar objects against occlusion?
1. Memory Pool module. Given a planar target, we reformulate the problem of tracking as predicting its mask and the ordered vertexes. The high-dimensional mask can accurately model the change of targets.
2. Appearance Perception. We use a dual-branch network to predict based on the historical tracking results. The masks are aggregated with a multi-layered layout, i.e., a stack of occluders and occludees.
3. Occlusion Reasoning. To solve the cases of complex occlusion, we indicate the occluded part by trajectory, which is predicted by factorized homography matrix, and then fuse the occluded area with the coarse results.
@inproceedings{zhang2023multiple,
title={Multiple Planar Object Tracking},
author={Zhang, Zhichang and Liu, Shengzhe and Yang, Jufeng},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2023}
}